Guava Cache是一款非常优秀的本地缓存框架。
这篇文章,我们聊聊如何使用 Guava Cache 异步刷新技巧带飞系统性能 。
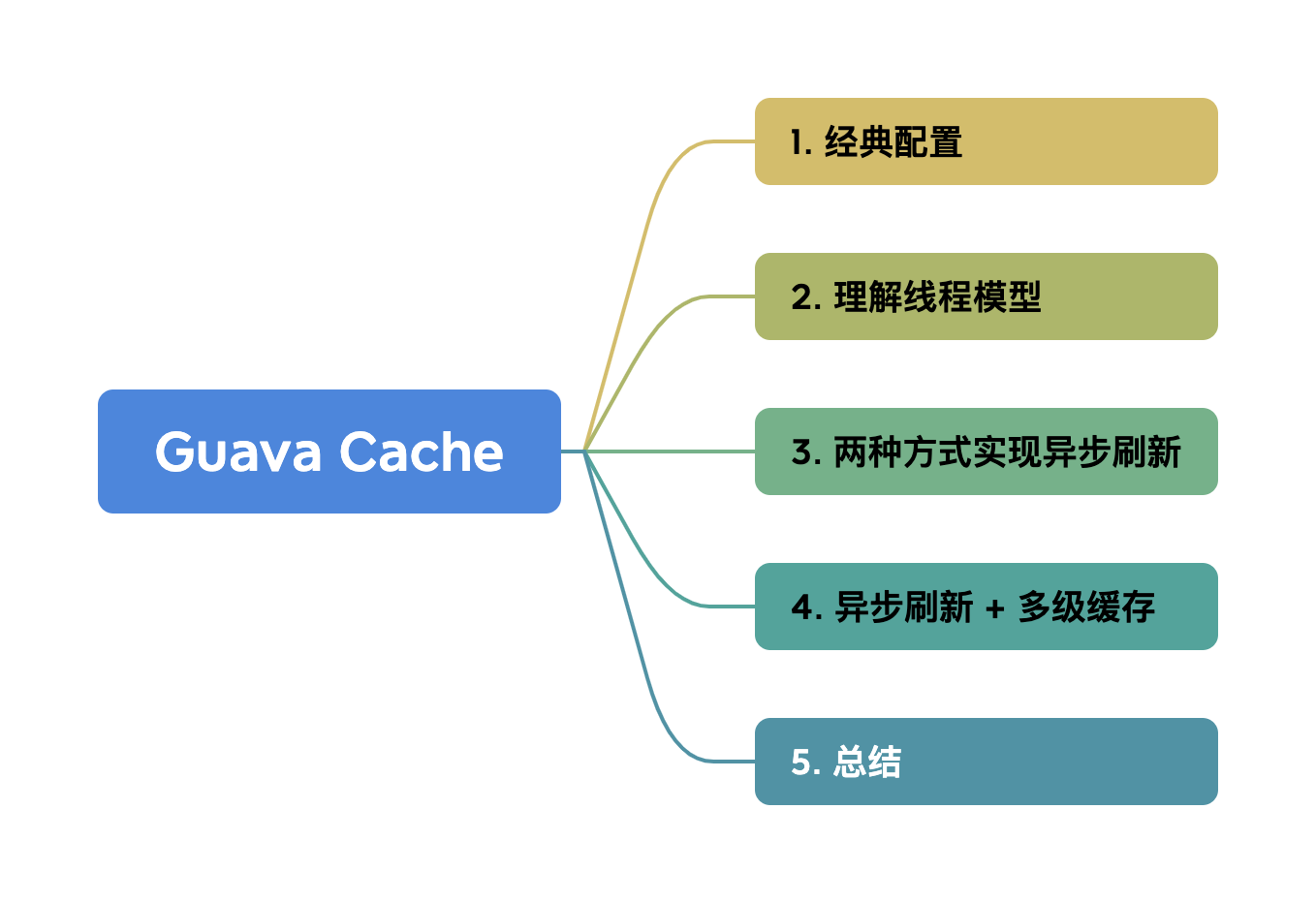
1 经典配置
Guava Cache 的数据结构跟 JDK1.7 的 ConcurrentHashMap 类似,提供了基于时间、容量、引用三种回收策略,以及自动加载、访问统计等功能。
大约 5 分钟
Guava Cache是一款非常优秀的本地缓存框架。
这篇文章,我们聊聊如何使用 Guava Cache 异步刷新技巧带飞系统性能 。
Guava Cache 的数据结构跟 JDK1.7 的 ConcurrentHashMap 类似,提供了基于时间、容量、引用三种回收策略,以及自动加载、访问统计等功能。
大家好,我是勇哥。
今天,我决定正式运营自己的知识星球 :勇哥的Java训练营 ,一个直播、服务型的知识星球。
知识星球是一个私密交流圈子,主要用途是知识创作者连接铁杆读者/粉丝。相比于微信群,知识星球易于内容沉淀、信息管理更高效。
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
数据分片流程由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
Guava Cache 是非常强大的本地缓存工具,提供了非常简单 API 供开发者使用。
这篇文章,我们将详细介绍 Guava Cache 的基本用法、回收策略,刷新策略,实现原理、实战招式。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
这篇文章,我们聊聊消息队列中非常重要的最佳实践之一:消费幂等。
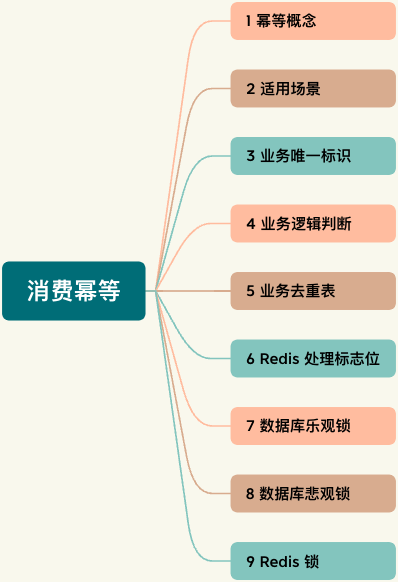
消费幂等是指:当出现 RocketMQ 消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消费并未对业务系统产生任何负面影响。
例如,在支付场景下,消费者消费扣款消息,对一笔订单执行扣款操作,扣款金额为100元。
这篇文章,我们聊聊如何设计一个 Redis 客户端 SDK 。

SDK 的设计理念核心两点:
提供精简的 API 供开发者使用,方便与用户接入;
屏蔽三方依赖,用户只和对外 API 层交互 。
Apache Commons Pool 提供了通用对象池的实现,用于管理和复用对象,以提高系统的性能和资源利用率。
对象池是一种设计模式,它维护一组已经创建的对象,并在需要时将其提供给应用程序,而不是每次需要时都创建新的对象。
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.0</version>
</dependency>
在 Spring Boot 项目中,数据库连接池已经成为标配,然而,我曾经遇到过不少连接池异常导致业务错误的事故。很多经验丰富的工程师也可能不小心在这方面出现问题。
在这篇文章中,我们将探讨数据库连接池,深入解析其实现机制,以便更好地理解和规避潜在的风险。
假如没有连接池,我们操作数据库的流程如下:
聊聊流式计算吧 , 那一段经历于我而言很精彩,很有趣,想把这段经历分享给大家。
2014年,我在艺龙旅行网促销团队负责红包系统。
彼时,促销大战如火如荼,优惠券计算服务也成为艺龙促销业务中最重要的服务之一。
而优惠券计算服务正是采用当时大名鼎鼎的流式计算框架 Storm。
流式计算是利用分布式的思想和方法,对海量“流”式数据进行实时处理的系统,它源自对海量数据**“时效”**价值上的挖掘诉求。